

EZRADIUS Resilience Update
 Keytos Team |
Keytos Team |
What was our Resiliency Plan Before the Incident?
Before this incident, we had taken into account that an outage could happen. Due to the sensitive nature of the service we provide, we have a multi-availability zone setup in all regions where we have customers. This means that if one availability zone goes down, the service will still be available in the other availability zones.
In addition to this, we have a caching system, which not only helps with the performance of the service but also mitigates the impact of an outage for our database provider or even Entra ID/Intune. Our services run with automated runners that check the health of the service every few seconds. If the service is not healthy, the runner will attempt to restart it (or, depending on the logs, take other actions known to restore the service). If the service remains unhealthy, the runner will send an alert to our on-call team.
What Happened on the 4th of February 2025?
On the 4th of February 2025, some customers experienced issues connecting to the EZRADIUS service. We first received reports from a customer that they were unable to connect to the service from some of their offices, while other offices were working fine.
Upon investigation, we confirmed that the service was up, running, and healthy. While on a call with that customer, we discovered that DownDetector was showing widespread reports of outages from different providers and cloud services. Further packet tracing from different locations revealed that there was an issue with packets reaching our service.
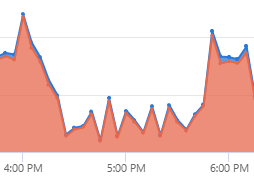
Overall, our analysis estimates that two-thirds of our U.S. customers were affected by this issue, along with about half of our Australian customers. Below, you can see the drastic drop in the number of requests to the service during the incident (in the graph, the red area represents accepted authentication requests, and the blue represents dropped authentication requests). As shown, there was a significant drop in packets between 4:30 PM and 5:45 PM EST before the service returned to normal levels.
What Did We Learn from the Incident?
There were multiple key learnings from this incident:
-
🔹 Customers did not know how to check the status of the service
During the outage, many customers reached out to their support engineer or used the chat on our site to check the service status. This made us realize that many customers are not aware of our status page, where they can check the status of all Keytos services. -
🔹 We Could Not Contact Some Customers
When we identified that some customers were having issues, we proactively emailed them to inform them that their network was unable to reach our services and suggested actions to mitigate the impact. However, some administrators had admin accounts without an associated email, preventing us from reaching them. -
🔹 Zone Reliability Is Not Enough
Our system was designed based on the SLAs of our cloud providers, ensuring that if a zone goes down, the service would still be available in another zone (our Kubernetes cluster can even automatically move nodes to available zones). However, we did not account for scenarios where an entire region experiences an internet outage or when a major fiber cut leads to severe packet loss due to congestion.
What are We Doing to Prevent This From Happening Again?
Now that we have experienced this, we must learn from it and take steps to prevent it from happening again. Here are some of the measures we are implementing:
-
🔹 Customers did not know how to check the status of the service
We are making our status page more prominent for new and existing customers. Additionally, our services already include a “health banner” that automatically deploys if a service health issue is detected. However, from this incident, we learned that allowing our engineers to manually add messages to that banner during outages would help customers stay informed without needing to contact us. -
🔹 We Could Not Contact Some Customers
We understand and even encourage the use of non-email-enabled admin accounts and PIM groups for managing our solutions. However, we are now adding a “notifications email” field on the settings page. We encourage customers to enter a team distribution list (DL) so we can notify them in case of future incidents.
-
🔹 Zone Reliability Is Not Enough
We have learned from our mistake of not having multi-region deployments (while keeping our data residency promises). Moving forward, all major public sites will have a secondary zone at a considerable distance from the primary region to minimize the risk of infrastructure issues causing outages. We encourage customers to check the new regions, as they may be closer than the existing ones. For RadSec, the URL has automatic failover between regions and directs requests to the closest server.
Closing Thoughts
The incident on the 4th of February 2025 was a wake-up call for us. We have learned valuable lessons and are taking steps to prevent a similar occurrence in the future.
We apologize for any inconvenience this may have caused and remain committed to providing the best possible service. If you have any questions or concerns, please do not hesitate to reach out to us.
Thank you for your understanding and continued support.